Neurodynamical models of the single-cell activity of body-selective visual neurons
Description:
The encoding of bodies in the superior temporal sulcus requires an encoding of body shape as well as of shape changes over time. We explore both aspects, starting with classical neurodynamical models and also exploiting state-of-the-art deep neural network models, which may help to understand the neural encoding in the brain.
First, we have built a physiologically inspired proof of concept model of body action recognition. Our model combines a front-end convolutional neural network (‘ShapeComp’ model; Morgenstern et al., PLOS Comp. Biol., 2021), trained to produce perceptually relevant shape features of objects, with a neurodynamical model based on a neural field framework that has previously been successful in reproducing dynamic properties of body action-selective neurons in the STS and premotor cortex. The model takes videos of silhouettes performing different actions as input, and the readout layer consists of high-level neurons that classify the various learned body actions.
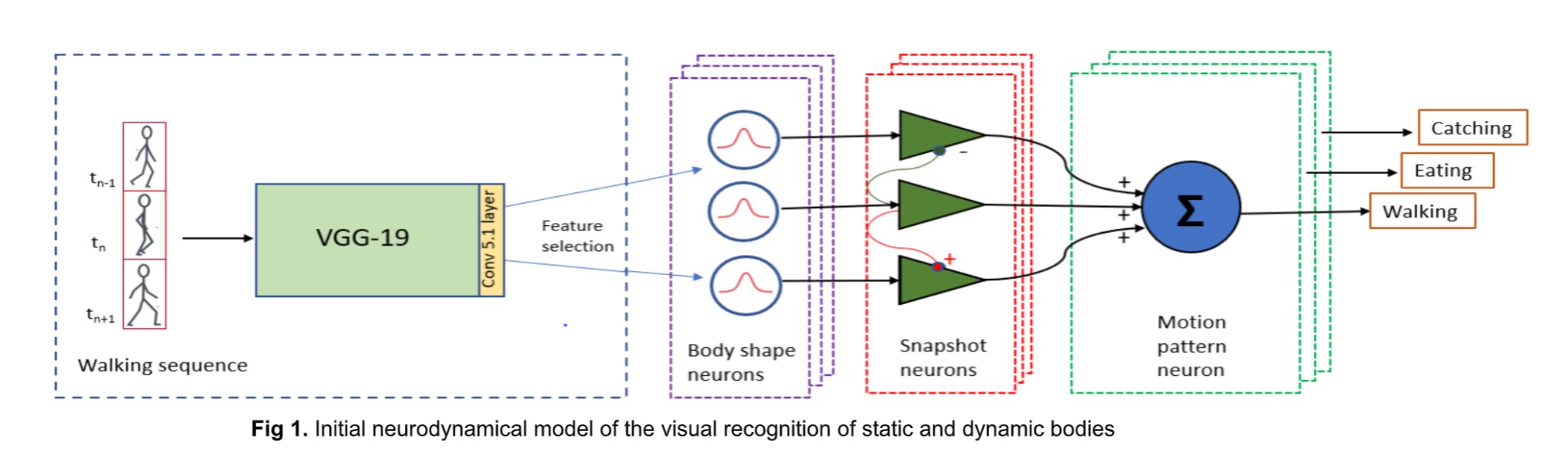
We initially tested some commonly used CNNs as alternative front-ends of our model. However, for the detection of body postures across individuals, we found that these networks did not facilitate robust recognition of the various key poses with invariance across different individuals when the model was trained only on moderately-sized data sets. Much more robust recognition of the body poses and actions could be achieved using the ShapeComp model as the front-end of the model.
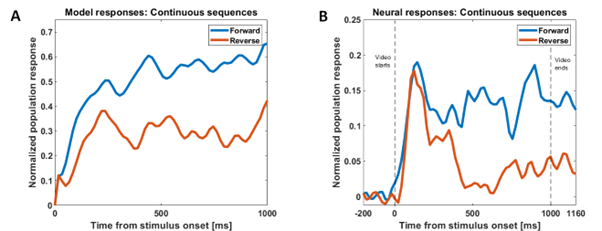
Our model successfully reproduces characteristics of single-unit responses (recorded by our collaborators at KU Leuven) from the rostral dorsal bank of the Superior Temporal Sulcus (AMUB body patch) at the population level. We have reproduced the sequence selectivity of the population response and also the disappearance of this sequence selectivity in the presence of large time gaps (blank frames) in the stimulus videos. Using analysis methods from linear neural field dynamics, we have also mathematically analyzed this dependence of sequence selectivity on gap duration.
 |
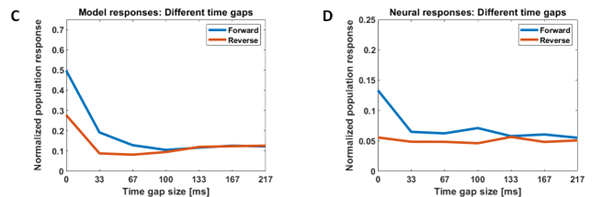 |
Figure 2: Modeling sequence-selectivity of neural population using videos presented in the correct temporal order (forward condition) and inverted temporal order (reverse condition) and the responses in the presence of time gaps of different durations
Second, we have also investigated how body shape might be encoded in the inferior temporal cortex (monkey area IT). Standard neural shape encoding models, including popular deep neural networks, do not account for the fact that humans recognize shapes, and especially bodies, even if they are not presented continuously over time. The extreme version of such asynchronous shape perception is anorthoscopic perception (Zöllner, 1862), where a shape is presented while translating behind a slit.
")
Figure 3: Anorthoscopic shape perception of bodies: The shape is presented asynchronously over time. At each moment only a small part of the shape is visible. However, humans readily recognize such shapes presented asynchronously, e.g., translating behind a slit (Zöllner, 1862).
Standard shape recognition models fail to account for this type of shape perception, which is readily accomplished by the human visual system. We have proposed a physiologically-inspired neural model that accounts for psychophysical properties of anorthoscopic perception as well as for the activity at the single-cell level of neurons in the inferotemporal cortex during anorthoscopic perception.
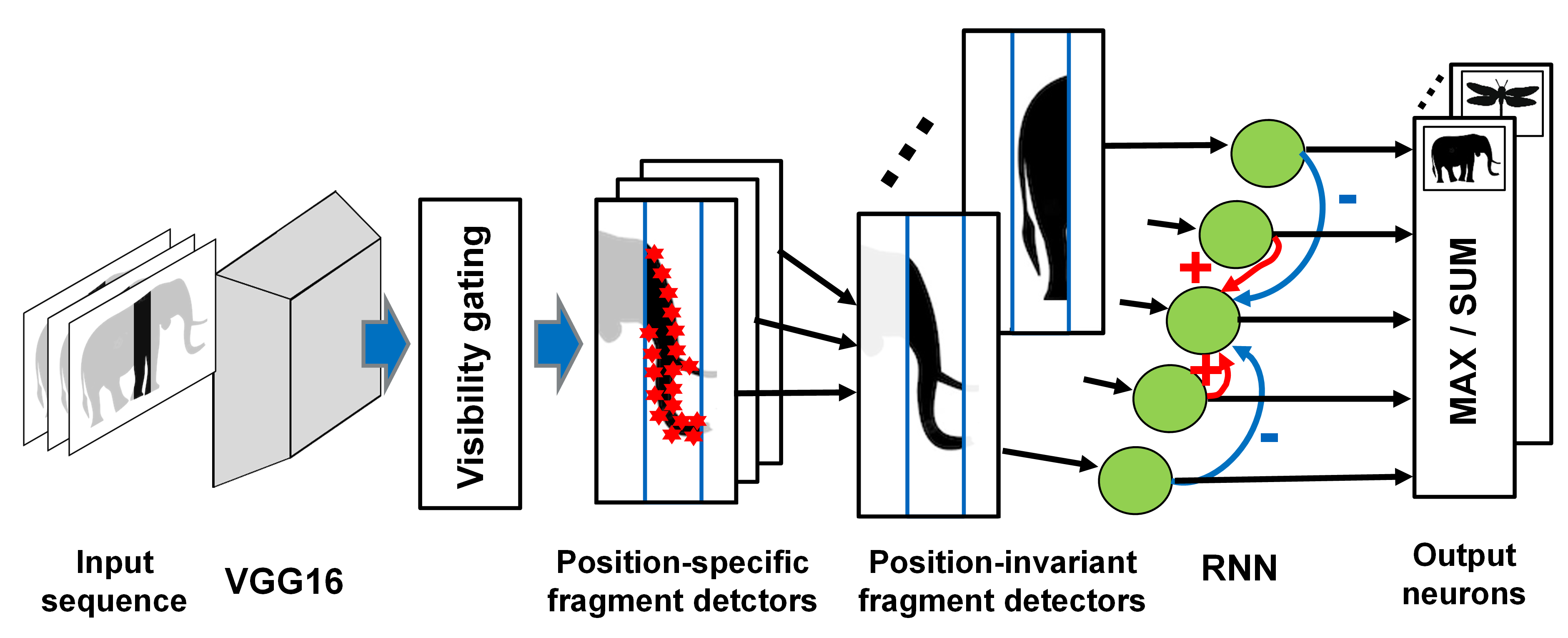
Figure 4: Neural model that accounts for the anorthoscopic recognition of body shape, and for associated electrophysiological data from area IT in monkey cortex.
As Convolutional Neural Networks (CNNs) are widely used as a model of core object recognition in primates, we are also studying whether CNNs can model neural responses in macaque body patches, and how the predictive power is related to training objective/data and model architecture. As dynamic body stimuli have a temporal dimension, candidate models must also have some notion of time. This introduces an exciting new aspect to the pursuit of a suitable model, as there are several different ways of introducing time dependency into a CNN.
") Figure 5: Neural model that accounts for the anorthoscopic recognition of body shape, and for associated electrophysiological data from area IT in monkey cortex.
Figure 5: Neural model that accounts for the anorthoscopic recognition of body shape, and for associated electrophysiological data from area IT in monkey cortex.
We are further using deep generative models to produce maximally exciting stimuli for single neurons in macaque body patches. This will be done in an online, closed-loop experiment. The approach will shed light on whether semantic, high-level body features are really necessary to drive the body patches at the single-cell level.